

The End of RAG?
New architectures and models emerging

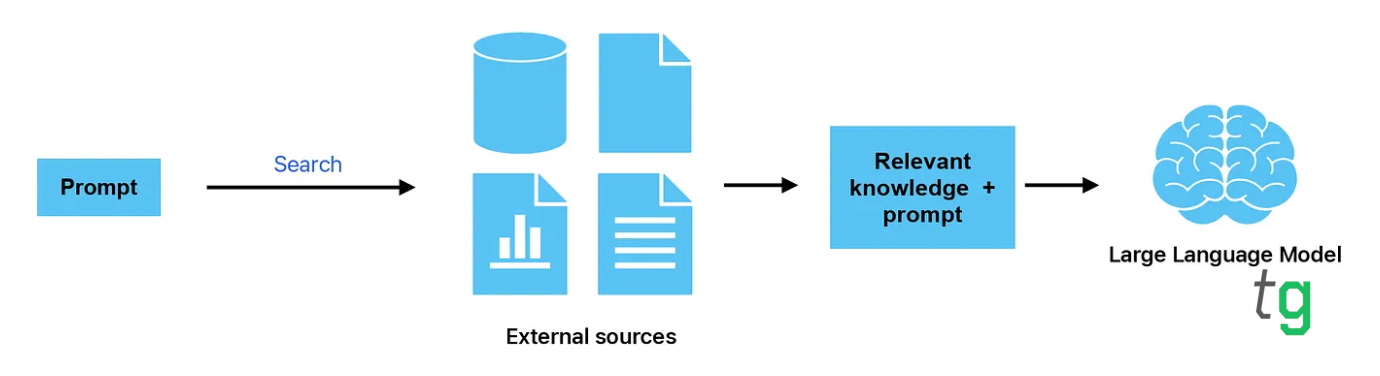
Retrieval augmented generation (RAG) has become a popular technique for improving the capabilities of large language models on knowledge-intensive tasks. By retrieving relevant information from a vector database by similarity and conditioning the LLM in this context, RAG provides factual grounding and mitigates hallucinations.
However, the core limitations that make RAG necessary may soon be overcome by advances in model architecture and scale.
My prediction is that in a year or two RAG as we know it today will be no longer be needed, as LLMs scale their context to unlimited sizes.
RAG emerged as a workaround for LLMs' limited context. LLMs have shown impressive few-shot learning capabilities, but their knowledge comes entirely from pre-training on internet text. This means they lack robust world knowledge and struggle on factual reasoning tasks. RAG adds dynamic external knowledge, enabling LLMs to generate more accurate, specific responses to knowledge-intensive prompts.
However, RAG introduces challenges of its own. The choice of embeddings, vector DB, and ranking algorithms is essential to obtaining good results.
Ultimately, RAG is a brittle patch attempting to compensate for LLMs' core limitations.
Rapid advances in model architecture and scale point towards LLMs soon overcoming these constraints intrinsically. Two key directions show particular promise.
Speeding up attention
First, innovating on the standard transformer attention mechanism. Attention quadratically scales compute with sequence length, limiting context size. But work on sparse attention, linear attention, and, more recently, Flash Attention shows the potential to greatly expand context capacity. LLM’s context size is increasing very rapidly.
In particular:
Yarn is an open source LLM that supports up to 128k context [1]
GPT-4-Turbo supports up to 128k context. [2]
Claude 2.1 now supports 200k context size (i.e. a book with around 300 pages!)[3]
As longer contexts become feasible, LLMs trained on broader sources can ingest far more knowledge themselves.
Similar techniques applied to broad world knowledge could make RAG's retrieved contexts redundant.
With contexts up to hundreds of pages, RAG can be replaced by just loading the whole document in the context.
Replacing Transformers
Another research direction is replacing transformers entirely with more capable architectures. Mamba [4] and RWKV [5] are two recent architectures that aim to replace the dominant Transformer architecture for sequence modeling tasks like language modeling. Both models are motivated by addressing the quadratic computational and memory complexity of self-attention in Transformers, instead using forms of linear attention to achieve linear scaling.
Mamba and RWKV are part of an emerging class of architectures that replace the quadratic self-attention mechanism in Transformers with more efficient linear attention variants. This allows them to scale linearly rather than quadratically.
Recurrent Weighted Key Value (RWKV) is a novel neural network architecture that combines the strengths of RNNs and transformers while mitigating their limitations. RWKV uses a linear attention mechanism for efficient memory usage and inference while allowing parallelized training like Transformers. Achieves O(n) complexity.
Mamba introduces a selection mechanism for structured state space models (SSMs) to allow them to perform context-dependent reasoning while scaling linearly.
The selection mechanism makes the SSM parameters input-dependent, allowing the model to selectively propagate or forget information.
By reducing the quadratic complexity of Transformers while aiming to maintain model effectiveness, Mamba and RWKV represent a promising research direction toward more efficient and scalable architectures for sequence modeling.
These advances won't eliminate RAG overnight. It will remain useful while LLMs still operate with limited context.
Within one or two years, RAG may shift from necessity to niche optimization as LLMs become more capable knowledge repositories themselves.
RAG allowed more knowledge to be included in the limited context of large language models. But if context capacity becomes virtually unlimited, RAG would be unnecessary, as the entire knowledge base could live within the LLM’s context window.
While a retrieval system might always be necessary to populate the context, the RAG architecture as we know it today with a vector database and text chunking might soon become obsolete.
RAG's current role reflects deficiencies in LLMs that steady progress is overcoming. As LLMs scale to unlimited context lengths, bandaging their limitation through a vector database will no longer be needed.